Creating Cohorts of Songs: How Spotify Finds What You’ll Love Next
-
Higher Education
Industry
-
Client
About the project.
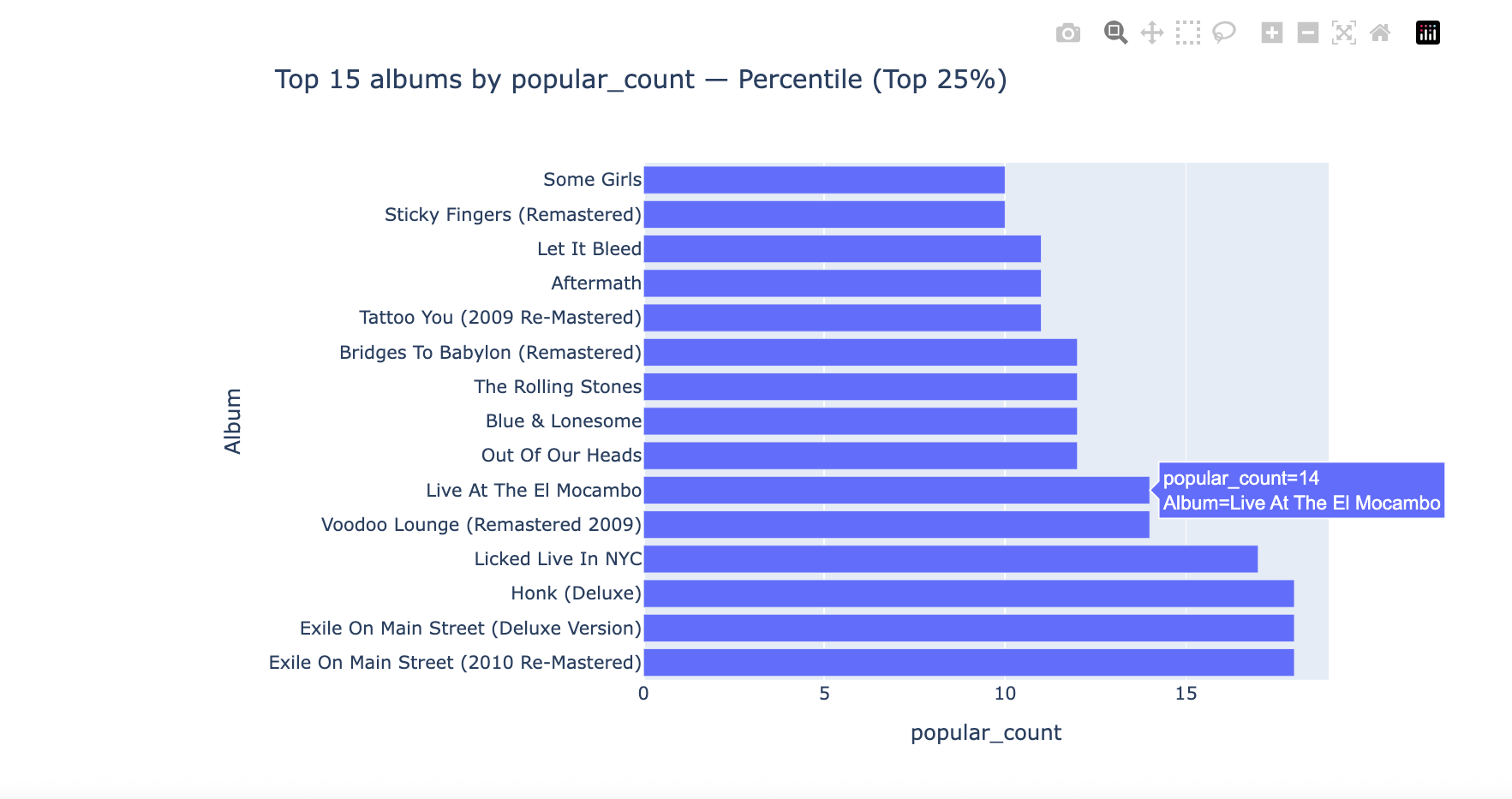
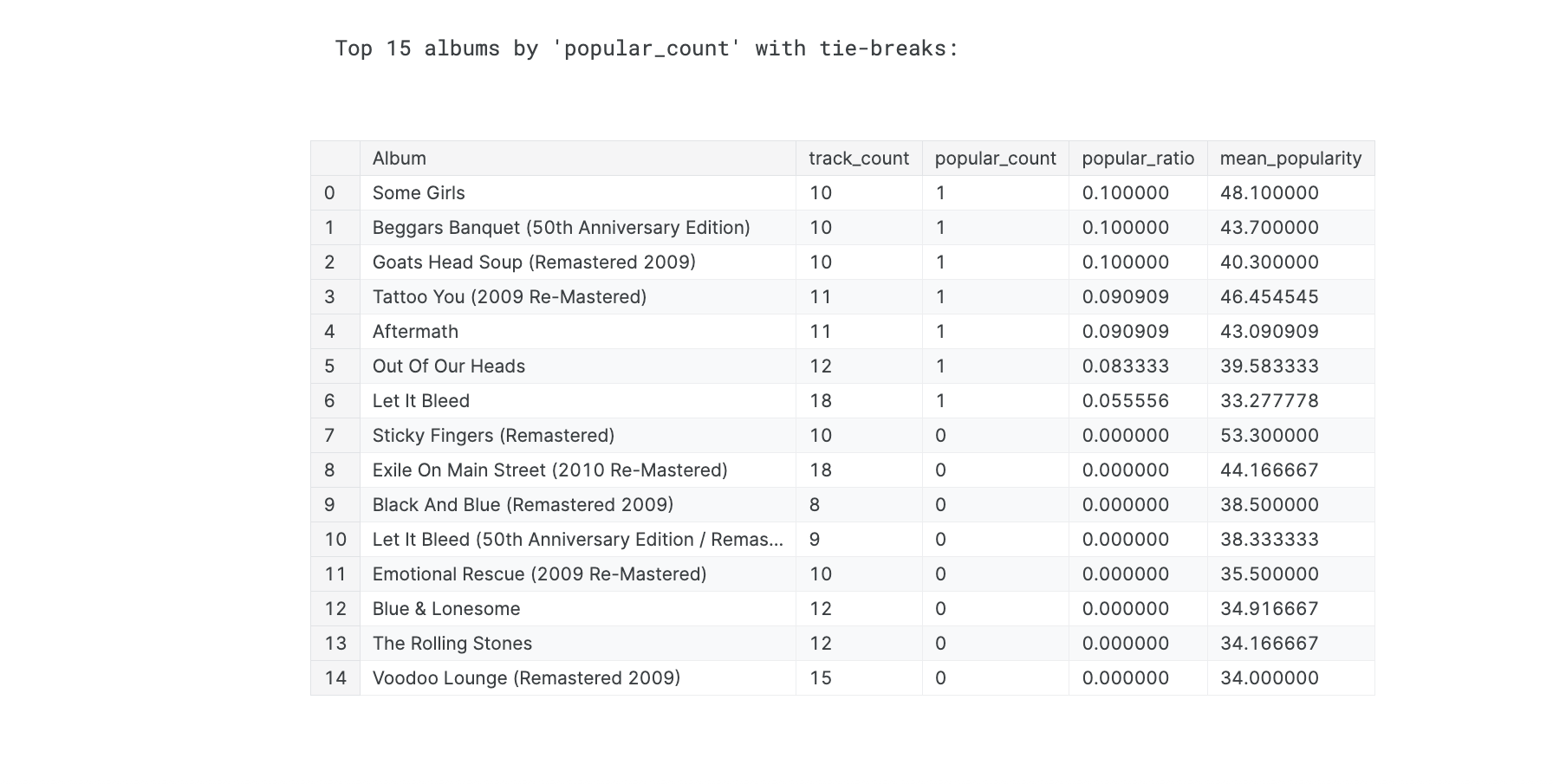
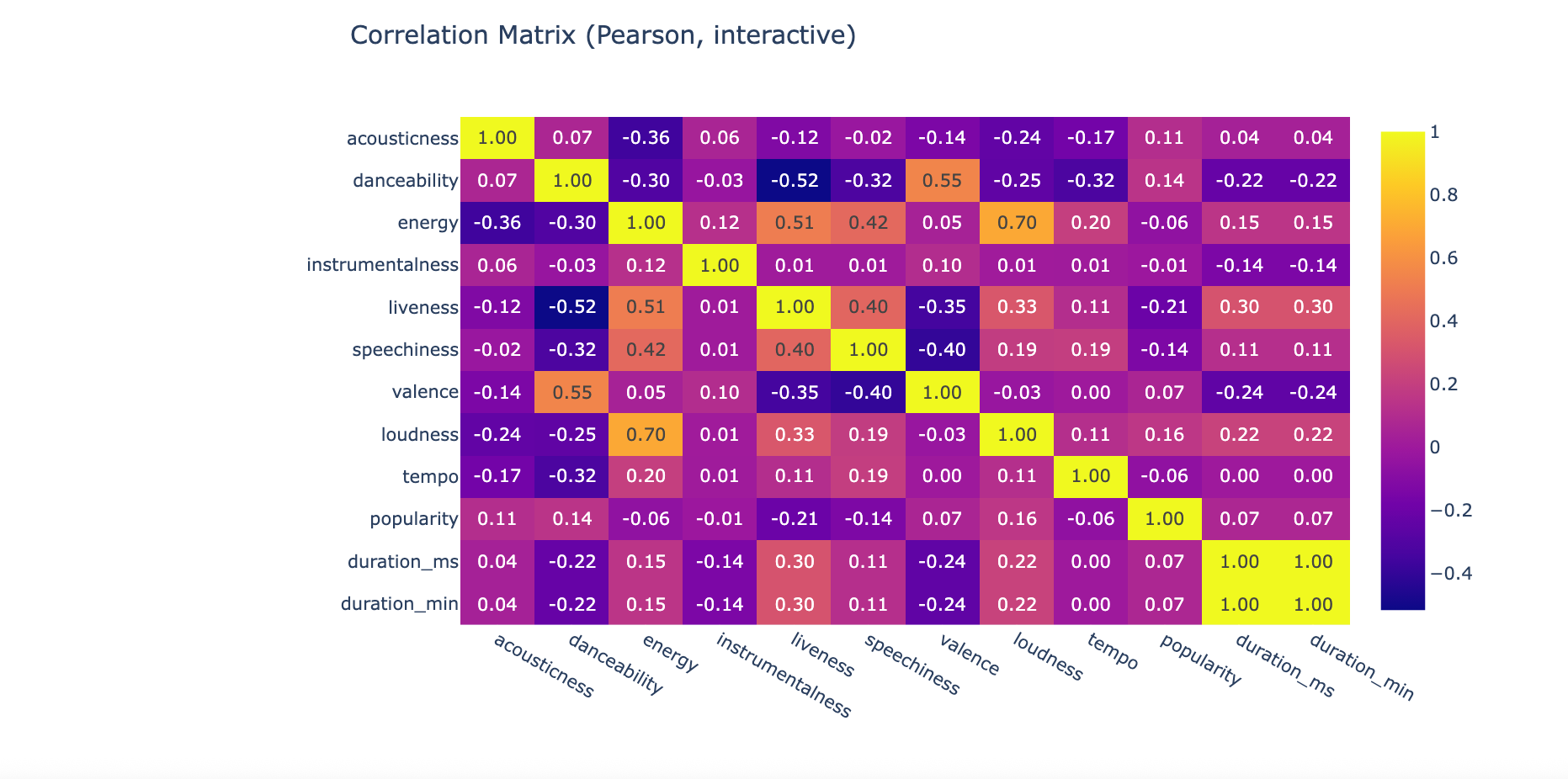
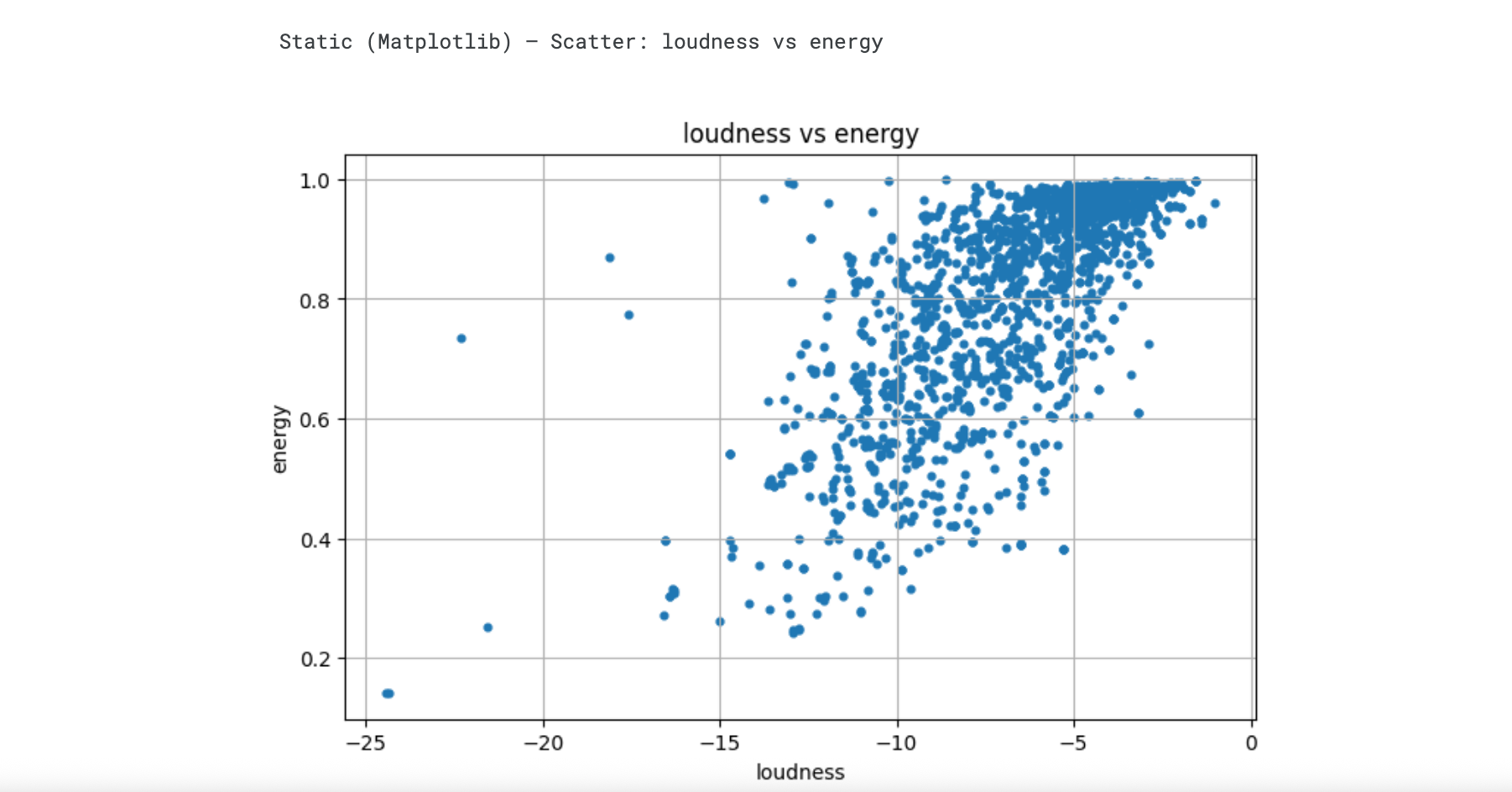
This project demonstrates how clustering algorithms can power intelligent recommendation systems. Using Spotify’s API data from The Rolling Stones discography as a case study, I explored how audio features and popularity metrics can be used to group songs with similar characteristics. Through exploratory data analysis, feature engineering, and unsupervised learning, the notebook showcases how platforms like Spotify identify and recommend “songs you might also like.”
Project Type
-
Machine Learning
-
Data Science & Engineering
-
Business Analytics
-
AI
Tech Stack / Toolbox
-
Python
-
Pandas
-
NumPy
-
scikit-learn
-
Matplotlib
-
Seaborn
-
Plotly
-
Reporting
-
SQL / ETL
My Role
Data Science & Machine Learning Engineer
-
Collected and cleaned Spotify API data for all Rolling Stones albums.
-
Performed EDA and feature engineering to explore correlations between audio traits and popularity.
-
Applied dimensionality reduction (PCA) and K-Means clustering to create song cohorts.
-
Visualized song similarity patterns to illustrate recommendation logic.
-
Interpreted clusters to show how streaming platforms personalize user experiences.